OpenAI’s Latest Voice Update: Outshining Siri and Alexa in the AI Revolution

OpenAI has just taken a monumental leap forward in the world of voice technology, bringing innovations that once belonged in the realm of science fiction directly to your fingertips. For those of us who cherish the beauty of seamless communication, these advancements are like discovering a treasure chest of possibilities. With the launch of three state-of-the-art audio models in its Realtime API—GPT-Realtime-2, GPT-Realtime-Translate, and GPT-Realtime-Whisper—OpenAI is inviting developers and users alike to reimagine how we interact with technology.
Elevating Voice Communication
So, what exactly are these new models capable of?
GPT-Realtime-2: The Game Changer
Leading the charge is GPT-Realtime-2, a revolutionary model that brings the reasoning capabilities of GPT-5 to live voice interactions. This means it can handle more complex requests while maintaining the flow of conversation, making it feel almost human.
- Multi-Tool Coordination: It can engage multiple tools effectively, narrating its actions with clarity, such as “checking your calendar” or “let me investigate that further.”
- Expanded Context: With a context window of 128K tokens, it allows for longer, more coherent sessions. Developers have the flexibility to adjust its reasoning effort, catering to various complexities in requests.
GPT-Realtime-Translate: Bridging Language Gaps
My personal favorite is the GPT-Realtime-Translate. This model brings us closer to the dream of a Universal Translator akin to what we admire in Star Trek.
- Live Speech Translation: Supporting over 70 input languages and 13 output languages, it performs real-time translations, even seamlessly switching when new speakers enter the conversation. Imagine a scenario where you can effortlessly communicate with someone speaking a different language—this model makes that vision a reality.
Image Credit: OpenAI
GPT-Realtime-Whisper: Instant Transcription
Last but certainly not least is the GPT-Realtime-Whisper model. While most speech-to-text models require the speaker to finish their thought for transcription, this one operates in real-time.
- Streaming Transcription: It captures and converts speech to text as the speaker talks. This feature is incredibly useful for live captions, meeting notes, or any dynamic scenario where waiting isn’t an option.
Accessibility of These State-of-the-Art Models
Currently, these advanced models are available for developers, who will shape how we experience voice AI in everyday applications. For example, a developer might create a real-time translator app that enhances conversations between speakers of different languages.
Several companies are already stepping up to utilize these new capabilities:
- Zillow is developing a voice assistant to facilitate home searches and schedule tours.
- Priceline is leveraging it to manage flight bookings and hotel reservations with single spoken requests.
- Vimeo is employing the technology for immediate transcription tasks.
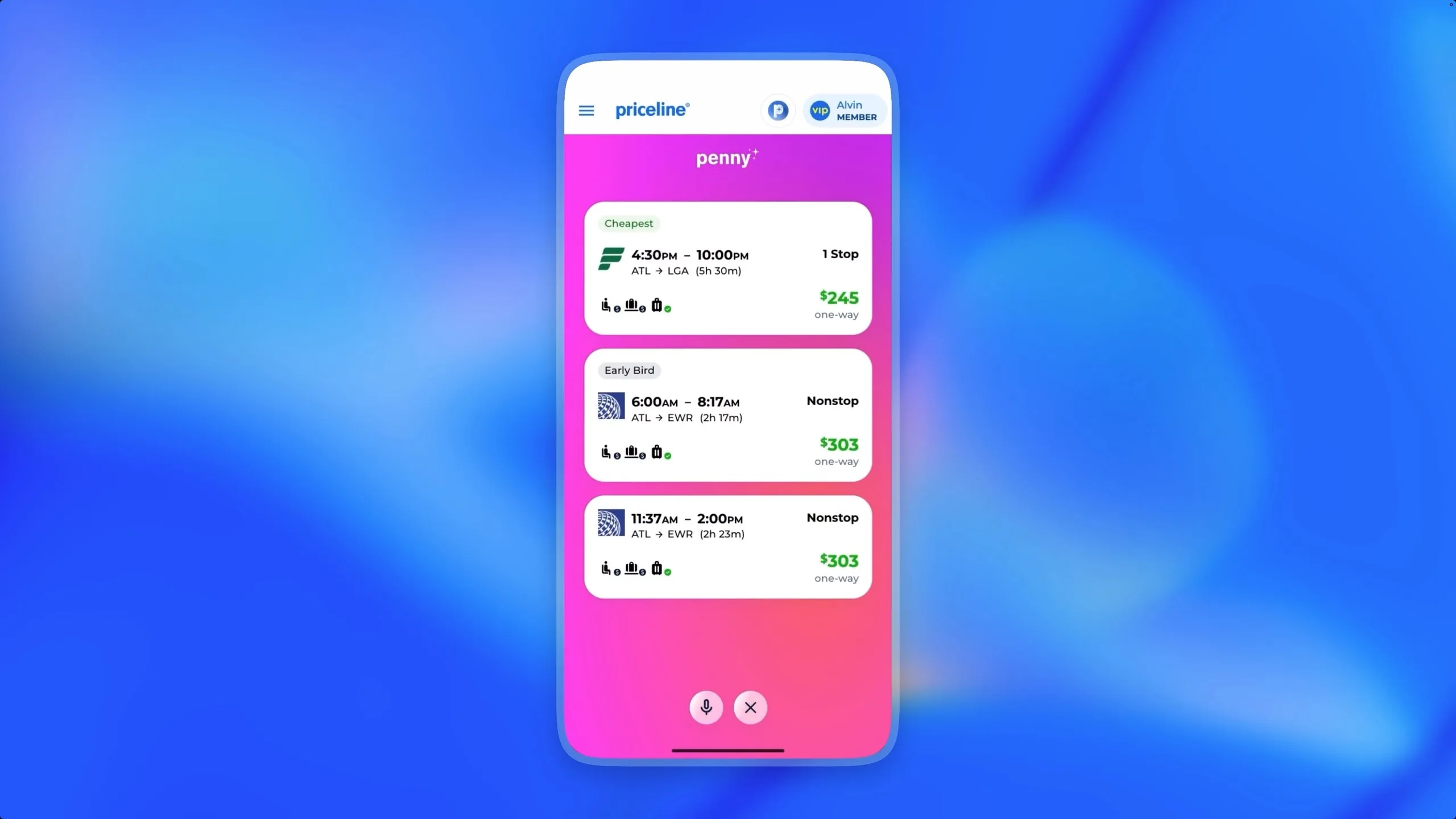
Image Credit: OpenAI
As for pricing, it starts at $0.017 per minute for the Whisper model, $0.034 per minute for the Translate model, and $32 per 1M audio input tokens for GPT-Realtime-2.
Embrace the Future of Voice Interaction
These revolutionary tools are set to redefine how we communicate, breaking barriers and enhancing our daily interactions. With each update, OpenAI is making the dream of seamless, efficient communication a reality.
Are you ready to dive into this new era of voice technology? Stay engaged and explore how these cutting-edge developments can enrich your daily life!